昨天寫的MapReduce並沒有放在Hadoop上跑,只有在Eclipse裡面跑,所以今天會把jar檔丟到Hadoop裡面,來看看執行的效果。
我也把檔案在累加為1.1GB (用虛擬機所以就沒放大檔摟),也可以看看分割Block的效果。
在前面有提到Hadoop的檔案儲存架構,會將一個檔案切成許多區塊(Blocks),所以我把1.1GB的檔案(cardinput.txt)存在HDFS上,按照內建的分割區塊大小(128MB),該檔案會被切成九個區塊。
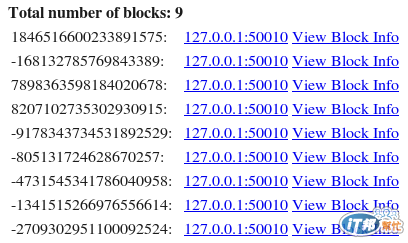
左邊這些數字,代表這個檔案真正存在檔案系統的名稱,後面127.0.0.1是代表該block的複本存放在那幾個node上,因為我只有一個node,所以只有一個。
接著我把昨天Cloudera的範例包成jar檔(不用包成Runnable Jar喔),還有把要運算的cardinput.txt放到對的路徑上(hdfs:/user/cloudera/cardinput.txt)。
在cli下執行
hadoop jar ./Card.jar CardDriver cardinput.txt output
./Card.jar 就是我剛才打包的jar檔,CardDriver則代表裡面要執行MapReduce的Class。
按下Enter之後,就會開始執行~

也可以透Map/Reduce administration 看運行的過程
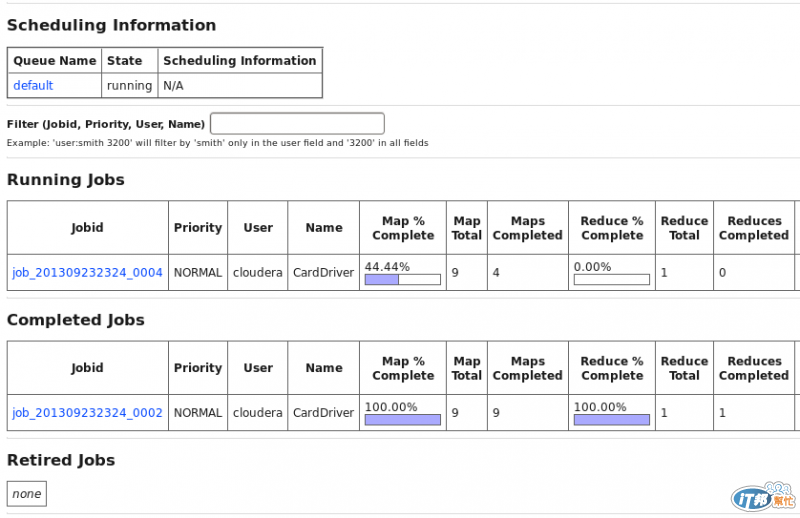
當完成後,Running Jobs 內的job 就會移到Completed Jobs

這邊可以注意到map的數量跟該檔案切割的區塊是一樣了,除了hdfs的區塊大小可以設定外,map的input大小也是可以設定了。如果用Cloudera的Hue,可以看到更漂亮的畫面 哈
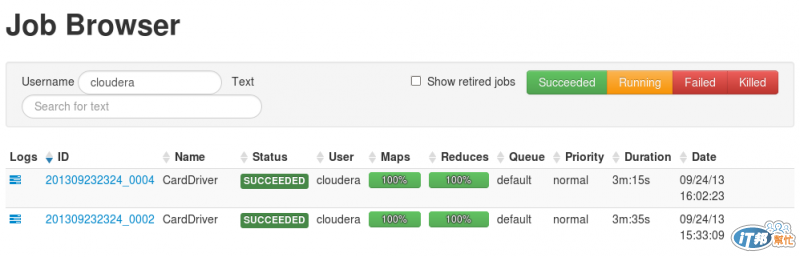
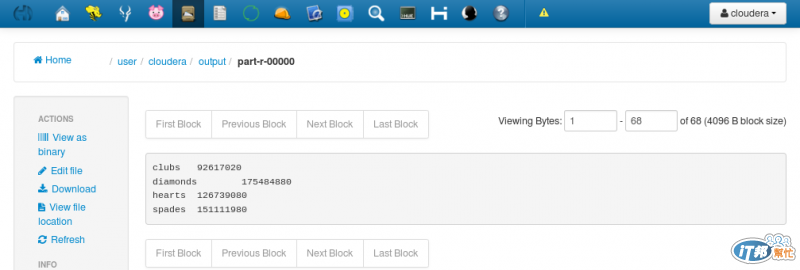
因為我把檔案放大了,所以結果當然也變多了,因為用虛擬機的關係,總共花了三分鐘多,
等上次佈署多一個node的問題解決,再來試看看速度是不是有變快。
今天先暫時到這,最近借了一本大數據的獲利模式感覺蠻好看了,
明天還要參加Hadoop in Taiwan 2013~,到時候再分享一些心得摟~


 iThome鐵人賽
iThome鐵人賽